{kind=link}
import os
if not os.path.exists('temp'):
os.makedirs('temp')Processing eReefs data
The effect of wind on surface current
Learn how to use eReefs data to answer the question ‘How strong does the wind need to be to set the direction of the surface ocean currents?’ in python.
Motivating problem
The East Australian Current (EAC) usually is a strong southward current near Myrmidon and Davies Reefs. During winter months the wind moves in a north eastern direction in the near opposite direction to the EAC. When the wind is low the surface currents are dominated by the EAC. As the wind picks up, at some speed the wind overpowers the EAC and the surface current moves in the direction of the wind.
We will use the AIMS eReefs extraction tool to extract data for two locations of interest:
Myrmidon Reef which is on the far outer edge of the GBR and is almost right in the middle of the southern Eastern Australian Current; and
Davies Reef which is further in the reef matrix, but in a similar sector of the GBR.
We then process the data and investigate the relationship between the strength of the wind and the direction of the surface currents for the two locations.
Analysis method
To determine the relation between the wind and the surface currents we will use the AIMS eReefs extraction tool to pull out hourly time series wind and current data for our two locations of interest. We will then look at the correlation between the wind and current vectors, where a correlation of 1 indicates they are pointing in the same direction, and -1 indicated they are in opposite directions.
Setting up to get the data
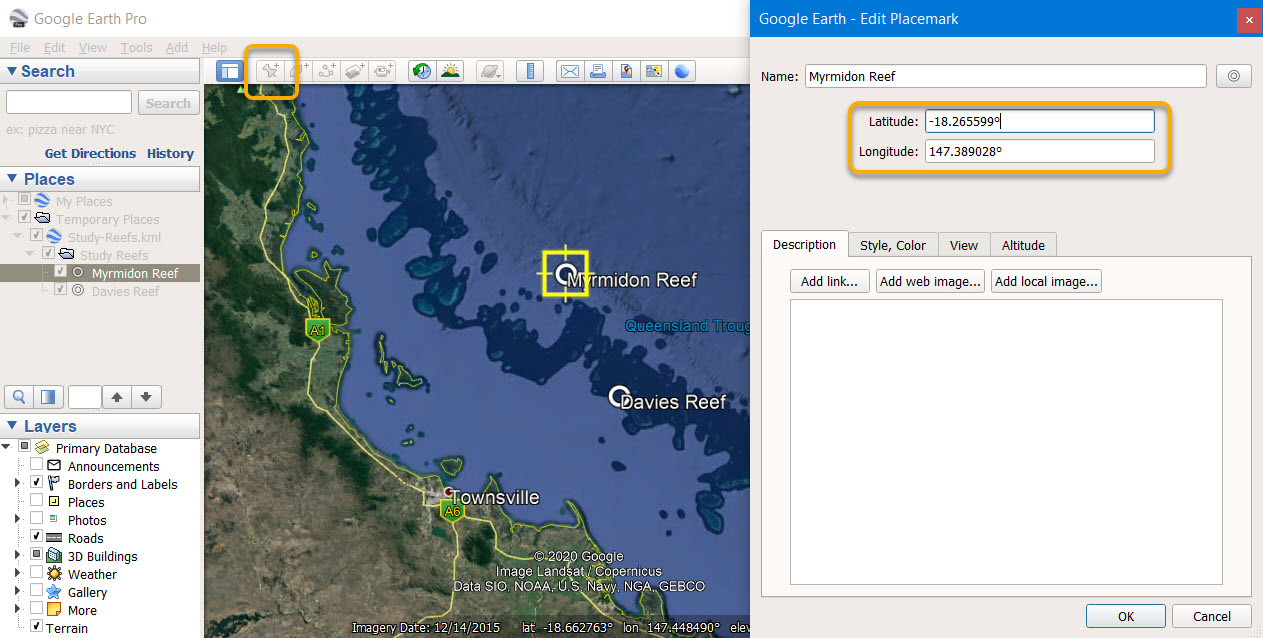
To extract the time series data using the extraction tool we need to create a CSV file containing the sites of interest. This file needs to contain the coordinates and names of the sites. To create this I first added my points manually in Google Earth Pro. This was done to simply get the location of Myrmidon and Davies Reefs. Using Google Earth to create your CSV file for the extraction tool is only useful if you don’t already know the coordinates of your sites.
Screenshot of Google Earth Pro with Myromidon and Davies reef sites
The points can be added using the Add placemark tool (looks like a pin). The locations can be seen by displaying the placemark properties. The resulting KML file can be found here: extraction-tool-locations.kml.
The location of the two sites were copied to create the CSV file for the data extraction tool.
Extracting the data
The CSV file was uploaded to the AIMS extraction tool and the extraction was performed with the following settings:
Data collection: GBR1 Hydro (Version 2)
Variables:
- Eastward wind speed (
wspeed_u) - Northward wind speed (
wspeed_v) - Northward current (
v) - Eastward current (
u)
- Eastward wind speed (
Date range: 1 January 2019 - 31 December 2019
Time step: hourly
Depths: -2.35 m
Once the extraction request was submitted the dataset was created after an one hour of processing the data was available for download from Extraction request: Example dataset: Wind-vs-Current at Davies and Myrmidon Reefs (2019).
Downloading the data
In this notebook we will download the data using scripting. There is no need to re-run the extraction request as each extraction performed by the extraction tool has a permanent public page created for it that can be used to facilitate sharing of the data.
Let’s first create a temporary folder to contain the downloaded data. Note: The temp folder is excluded using the .gitignore so it is not saved to the code repository, which is why we must reproduce it.
Now let’s download the data. The file to download is 12.9 MB and so this download might take a little while. To allow us to re-run this script without having to wait for the download each time we first check that the download has not already been done.
import urllib.request
extractionfile = os.path.join('temp','2009.c451dc3-collected.csv') # Use os.path.join so the script will work cross-platform
if not os.path.exists(extractionfile):
print("Downloading extraction data ...")
url = 'https://api.ereefs.aims.gov.au/data-extraction/request/2009.c451dc3/files/2009.c451dc3-collected.csv'
req = urllib.request.urlretrieve(url, extractionfile)
print(req)
else:
print("Skipping redownloading extraction data")Skipping redownloading extraction dataReading and cleaning the data
Read the resulting CSV file into a Pandas data frame.
import pandas as pd
from janitor import clean_names
df = pd.read_csv(extractionfile).clean_names()print(repr(df.head()))| aggregated_date_time | variable | depth | site_name | latitude | longitude | mean | median | p5 | p95 | lowest | highest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-01-01T00:00 | wspeed_u | 99999.90 | Myrmidon Reef | -18.265599 | 147.389028 | -9.568488 | -9.568488 | -9.568488 | -9.568488 | -9.568488 | -9.568488 |
| 1 | 2019-01-01T00:00 | wspeed_u | 99999.90 | Davies Reef | -18.822840 | 147.645209 | -8.880175 | -8.880175 | -8.880175 | -8.880175 | -8.880175 | -8.880175 |
| 2 | 2019-01-01T00:00 | wspeed_v | 99999.90 | Myrmidon Reef | -18.265599 | 147.389028 | 3.260430 | 3.260430 | 3.260430 | 3.260430 | 3.260430 | 3.260430 |
| 3 | 2019-01-01T00:00 | wspeed_v | 99999.90 | Davies Reef | -18.822840 | 147.645209 | 2.756750 | 2.756750 | 2.756750 | 2.756750 | 2.756750 | 2.756750 |
| 4 | 2019-01-01T00:00 | v | -2.35 | Myrmidon Reef | -18.265599 | 147.389028 | 0.047311 | 0.047311 | 0.047311 | 0.047311 | 0.047311 | 0.047311 |
The first thing we might notice about the data is that, somewhat confusingly, we have a bunch of aggregation statistics (mean, median, p5, p95, lowest, highest) which all take the same value. This is because we have extracted hourly “aggregated” data, but the time step for the eReefs model is also hourly. Therefore each row represents an aggregation over a single data point. Don’t worry if you are confused by this, it’s not important. Just think of this as a quirk of the eReefs data extraction tool. We’ll clean this up now by replacing the aggregation statistics with a single column called value and rename aggregated_date_time to date_time, to avoid any further confusion.
# Create 'value' column, remove aggregation statistic columns, rename aggregated_date_time
df2 = df.\
assign(value = df['mean']).\
drop(columns=['mean', 'median', 'p5', 'p95', 'lowest','highest']).\
rename(columns={"aggregated_date_time": "date_time"})print(repr(df2.head()))| date_time | variable | depth | site_name | latitude | longitude | value | |
|---|---|---|---|---|---|---|---|
| 0 | 2019-01-01T00:00 | wspeed_u | 99999.90 | Myrmidon Reef | -18.265599 | 147.389028 | -9.568488 |
| 1 | 2019-01-01T00:00 | wspeed_u | 99999.90 | Davies Reef | -18.822840 | 147.645209 | -8.880175 |
| 2 | 2019-01-01T00:00 | wspeed_v | 99999.90 | Myrmidon Reef | -18.265599 | 147.389028 | 3.260430 |
| 3 | 2019-01-01T00:00 | wspeed_v | 99999.90 | Davies Reef | -18.822840 | 147.645209 | 2.756750 |
| 4 | 2019-01-01T00:00 | v | -2.35 | Myrmidon Reef | -18.265599 | 147.389028 | 0.047311 |
Much better! Now it is clear to see that the data is in long format. That is, a single row for each value and a separate column describing the meaning of the value — in this case the column variable describes what the column value means. Converting the data into tidy format will help with subsequent analyses (and is probably also the format you are most comfortable working with). When data is in tidy format, each variable has its own column, each observation has its own row, and each value has its own cell.
If we think of the wind and current velocities as the things being “measured”, then the observations in the dataset are the values of the measurements for each time point at each site. Therefore we would like a single row for each unique combination of date_time and site_name (or latitude and longitude pair). Let’s see if this is what we get we try to “widen” the data into tidy format.
# Try pivoting the data into tidy format
df2_pivot = df2.pivot(
index = ["site_name", "latitude", "longitude", "date_time", "depth"],
columns="variable",
values="value"
)print(repr(df2_pivot.head()))| variable | u | v | wspeed_u | wspeed_v | ||||
|---|---|---|---|---|---|---|---|---|
| site_name | latitude | longitude | date_time | depth | ||||
| Davies Reef | -18.82284 | 147.645209 | 2019-01-01T00:00 | -2.35 | -0.048835 | 0.100391 | NaN | NaN |
| 99999.90 | NaN | NaN | -8.880175 | 2.756750 | ||||
| 2019-01-01T01:00 | -2.35 | -0.090807 | -0.036129 | NaN | NaN | |||
| 99999.90 | NaN | NaN | -8.749271 | 2.753487 | ||||
| 2019-01-01T02:00 | -2.35 | -0.118289 | -0.180480 | NaN | NaN |
With all the NAs in the wind and current speed columns, this doesn’t look tidy at all! And it’s because we forgot to account for depth. However, we can notice that depth is actually a redundant variable in this dataset. That’s because wind speed implies a NA depth value (coded as 10000m in the extracted data) and current implies a depth of -2.35m (as this is the only depth we chose to extract). Therefore we can just remove depth entirely from our dataset without losing any information, that is, as long as we remember that the current relates to a depth of -2.35m. For the forgetful among us, we could rename the current variables to v_2.35m and u_2.35m. In fact moving the depth into the variable names would be a good solution to create a tidy dataset if we had selected multiple depths.
# Pivot into tidy format (excluding depth)
df_tidy = df2.pivot(
index = ["site_name", "latitude", "longitude", "date_time"],
columns="variable",
values="value"
)print(repr(df_tidy.head()))| variable | u | v | wspeed_u | wspeed_v | |||
|---|---|---|---|---|---|---|---|
| site_name | latitude | longitude | date_time | ||||
| Davies Reef | -18.82284 | 147.645209 | 2019-01-01T00:00 | -0.048835 | 0.100391 | -8.880175 | 2.756750 |
| 2019-01-01T01:00 | -0.090807 | -0.036129 | -8.749271 | 2.753487 | |||
| 2019-01-01T02:00 | -0.118289 | -0.180480 | -8.463824 | 2.587230 | |||
| 2019-01-01T03:00 | -0.110750 | -0.278911 | -8.223801 | 2.112059 | |||
| 2019-01-01T04:00 | -0.079472 | -0.312360 | -8.565171 | 2.711215 |
Much better! Now each row gives the wind and current speeds for different sites at different points in time.
Correlation
Our aim is to create an index that estimates the correlation of the current and the wind vectors.
The correlation of the current and wind vectors can be estimated based using the dot product. An overview of the relationship between correlation and using the dot product is described in Geometric Interpretation of the Correlation between Two Variables. The correlation between the two vectors is given by:
\[ r = \cos(\theta) = \frac{a \cdot b}{||a||\cdot||b||} \]
where \(a \cdot b\) is the dot product between the two vectors and \(||a||\) and \(||b||\) are the magnitudes of the vectors. The dot product can be calculated as
\[ a \cdot b = a_x \times b_x + a_y \times b_y \]
and the magnitude of the vectors as
\[ ||a|| = \sqrt{a^2_x + a^2_y} \;\;, \; \;\;\;\; ||b|| = \sqrt{b^2_x + b^2_y} \]
import numpy as np
df_corr = df_tidy
df_corr['currentmag'] = np.sqrt(df_corr['u']**2 + df_corr['v']**2)
df_corr['windmag'] = np.sqrt(df_corr['wspeed_u']**2 + df_corr['wspeed_v']**2)
df_corr['windcurrentcorr'] = (df_corr['u'] * df_corr['wspeed_u'] + df_corr['v'] * df_corr['wspeed_v']) / (df_corr['currentmag'] * df_corr['windmag'])print(repr(df_corr.head()))| variable | u | v | wspeed_u | wspeed_v | currentmag | windmag | windcurrentcorr | |||
|---|---|---|---|---|---|---|---|---|---|---|
| site_name | latitude | longitude | date_time | |||||||
| Davies Reef | -18.82284 | 147.645209 | 2019-01-01T00:00 | -0.048835 | 0.100391 | -8.880175 | 2.756750 | 0.111638 | 9.298236 | 0.684380 |
| 2019-01-01T01:00 | -0.090807 | -0.036129 | -8.749271 | 2.753487 | 0.097730 | 9.172319 | 0.775325 | |||
| 2019-01-01T02:00 | -0.118289 | -0.180480 | -8.463824 | 2.587230 | 0.215790 | 8.850428 | 0.279727 | |||
| 2019-01-01T03:00 | -0.110750 | -0.278911 | -8.223801 | 2.112059 | 0.300094 | 8.490683 | 0.126259 | |||
| 2019-01-01T04:00 | -0.079472 | -0.312360 | -8.565171 | 2.711215 | 0.322311 | 8.984033 | -0.057391 |
Let’s look at the relationship between the wind and current as a function of the wind speed. Here we are considering each hourly sample as an independent estimate of the relationship. In reality this is not the case as the longer the wind blows the more effect it will have on the current. As this is just a coding example and not an in-depth analysis we don’t need to worry about this limitation of the analysis.
Let’s pull out the data for Davies and Myrmidon Reefs separately so they are easy to plot.
davies = df_corr.query('site_name == "Davies Reef"')
myrmidon = df_corr.query('site_name == "Myrmidon Reef"')print(repr(myrmidon.head()))| variable | u | v | wspeed_u | wspeed_v | currentmag | windmag | windcurrentcorr | |||
|---|---|---|---|---|---|---|---|---|---|---|
| site_name | latitude | longitude | date_time | |||||||
| Myrmidon Reef | -18.265599 | 147.389028 | 2019-01-01T00:00 | 0.012498 | 0.047311 | -9.568488 | 3.260430 | 0.048934 | 10.108727 | 0.070078 |
| 2019-01-01T01:00 | -0.029212 | -0.013297 | -9.420339 | 3.528335 | 0.032096 | 10.059420 | 0.707019 | |||
| 2019-01-01T02:00 | -0.060520 | -0.066542 | -9.333500 | 3.765564 | 0.089947 | 10.064477 | 0.347188 | |||
| 2019-01-01T03:00 | -0.078321 | -0.111699 | -9.281394 | 3.784521 | 0.136421 | 10.023316 | 0.222466 | |||
| 2019-01-01T04:00 | -0.076759 | -0.132760 | -8.527690 | 3.885759 | 0.153353 | 9.371266 | 0.096513 |
Let’s create a scatter plot to see if there is a relationship between the wind and currents.
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(myrmidon["windmag"], myrmidon["windcurrentcorr"], color='r', s=1)
ax.scatter(davies["windmag"], davies["windcurrentcorr"], color='b', s=1)
ax.set_xlabel('Wind speed (m/s)')
ax.set_ylabel('Wind-current correlation')
ax.set_title('Correlation between wind and surface current (hourly data, 2019)')
plt.tight_layout()
plt.show()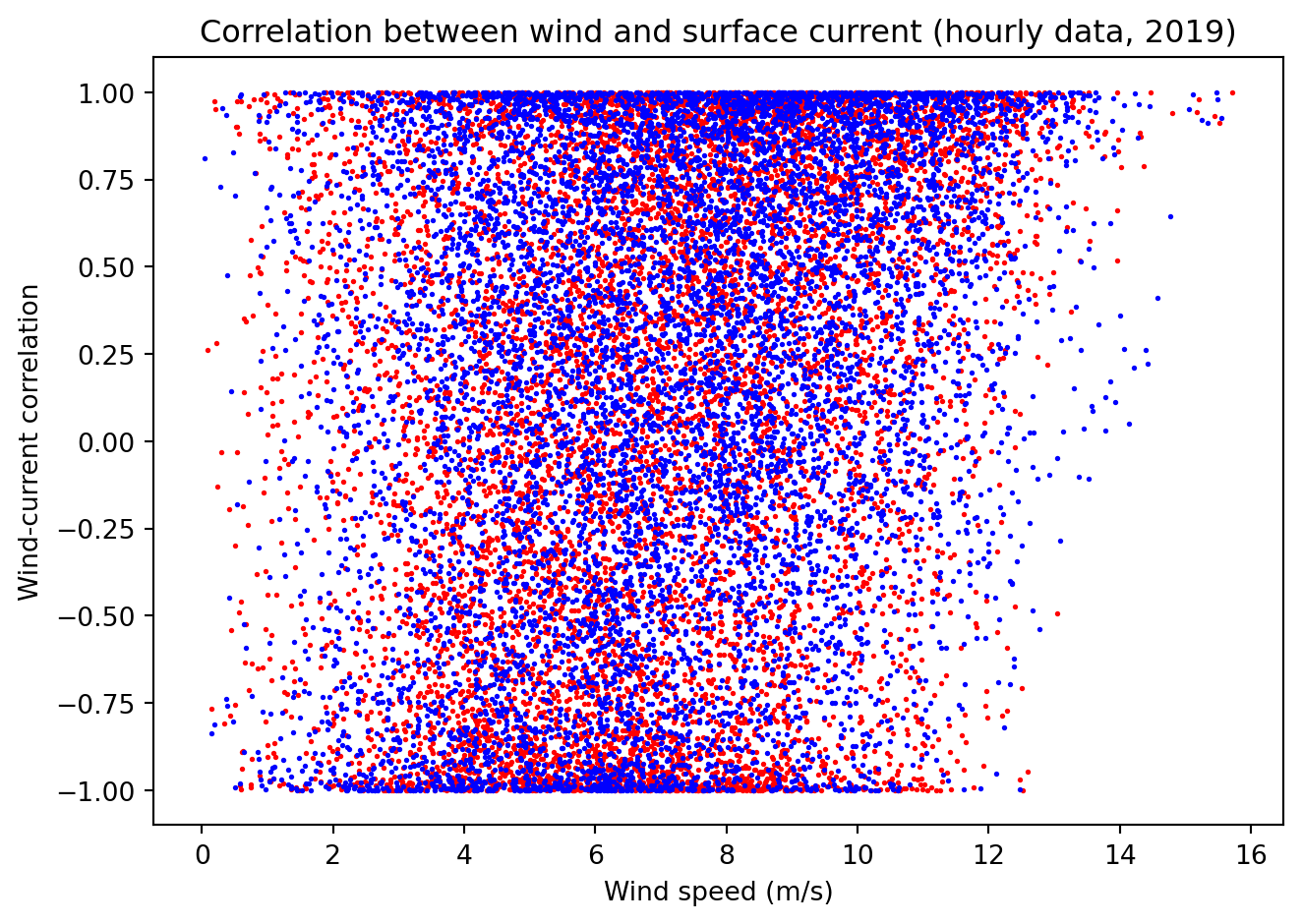
This scatter plot shows that the relationship between wind and current is weak. This is not surprising given that we are considering just the hourly samples, with no consideration for how long the wind has been blowing. At low wind conditions the current has an even chance of being aligned with the wind (correlation \(r= 1\)) as in the opposite direction (correlation \(r= -1\)), however in high wind we can see that there is much more chance that the currents are aligned with the wind.
To understand this relationship better we want to understand how much the wind nudges the current in its direction. If we bin the wind speeds then collect all the correlation samples in each bin then we can see if they average to zero (indicating that there is no relationship between the wind and current) or there is average alignment.
from scipy import stats
wind = davies["windmag"]
current = davies["windcurrentcorr"]
bin_means, bin_edges, binnumber = stats.binned_statistic(wind, current, 'mean', bins=20)
plt.hlines(bin_means, bin_edges[:-1], bin_edges[1:], colors='g', lw=5,
label='Davies Reef')
wind = myrmidon["windmag"]
current = myrmidon["windcurrentcorr"]
bin_means, bin_edges, binnumber = stats.binned_statistic(wind, current, 'mean', bins=20)
plt.hlines(bin_means, bin_edges[:-1], bin_edges[1:], colors='r', lw=5,
label='Myrmidon Reef')
plt.xlabel('Wind speed (m/s)')
plt.ylabel('Wind-current correlation')
plt.title('Mean correlation between wind and surface current (hourly data, 2019)')
plt.legend()
plt.show()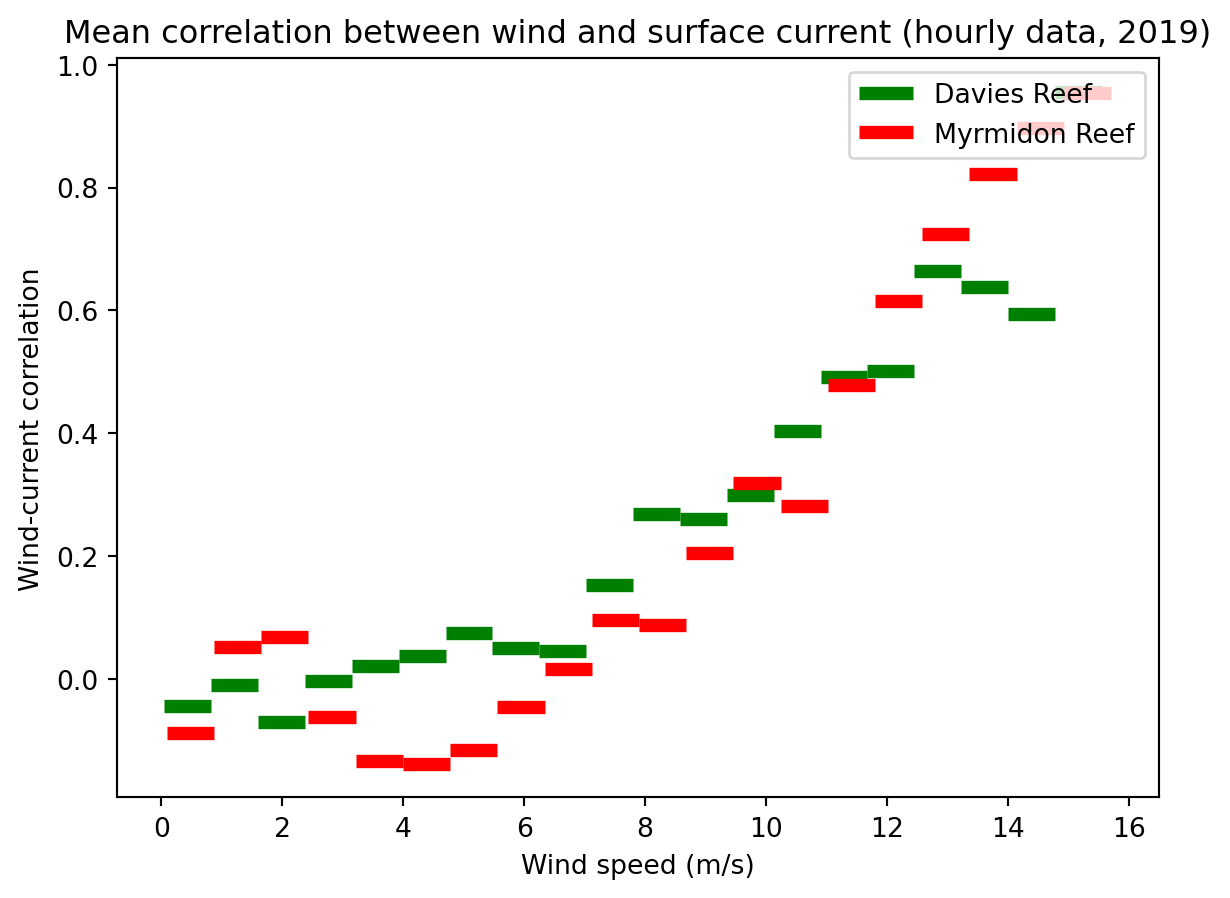
From this we can see that for wind speeds below about 8 m/s the surface current direction is unrelated to the wind. Above this wind speed the surface current is increasingly determined by the direction of the wind. By the time the wind is 16 m/s the direction of the surface current is dominated by the wind direction.
It should be remembered that this analysis is based on the eReefs Hydrodynamic model and as such is not based on real data. The eReefs model has however been tuned to accurately capture the flow dynamics of the GBR and so we would expect the estimates from this analysis to be approximately correct.